
你是不是也遇過這種畫面。
AI 產出一整串「可能性」。像開了水龍頭。停不下來。
主管看著你。投資人看著你。你自己也看著你。😑
問題是。沒有一個東西真的被「驗證」。
就卡在那個最土、最慢、最花錢的步驟。
做實驗。跑流程。等結果。
AI 讓「想」變便宜,真正貴的是「證明」
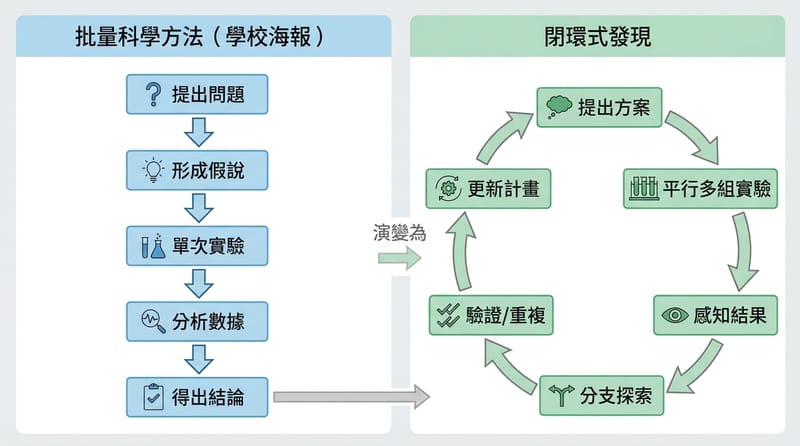
Artificial Discovery 指的是把 AI 的推論能力接到自動化實驗與真實世界回饋迴路,讓「提出假設→測試→迭代→得到可驗證新知」變得可規模化。當大型語言模型讓思考成本下降,稀缺資源會轉成實體執行、測試速度、與迭代效率。
- 你在買的不是 AI:你在買「更快的驗證迴路」
- 瓶頸換地方:從思考變成執行、測試、重跑、排程
- 差別點:不是 AGI、不是 AI Agent 寫 code 而已,是實驗會回嘴、流程會轉彎
- 殘酷現實:假設可以一天生一萬個,濕實驗驗一個要幾週
講到「驗證」:我就會想到那種最常見的地獄。
你把 protocol 寫在方法學段落。或 PDF。或某個人的腦袋裡。
接著你要把它變成機器能跑的東西。
你開始搬資料。CSV。Excel。再匯回去。
欄位對不上。再一次。
真的。就這樣浪費一週。
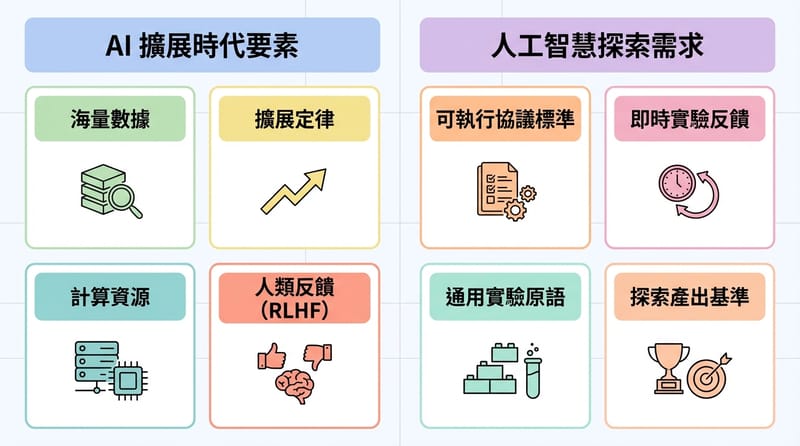
為什麼 AI 這幾年會突然爆衝,實驗世界卻像停在 2012
大型語言模型的躍進來自四個要素一起到位:大量原始資料、可預測的 scaling law、足夠算力、加上 RLHF 這種人類回饋閉環。把這套搬到實驗科學,缺的通常不是「聰明」,缺的是可標準化的實驗輸入、可重複的回饋迴路、與能被投資人相信的吞吐量對發現曲線。
原始資料:網頁、書、維基百科。電子跑很快。成本低。
濕實驗資料:要試劑。要時間。要人。還要運氣。
差別在這。
你想把「加 10 倍資源就多 10 倍成果」講成定律。
在 wet lab 很難講出口。
插一個現場感:很多實驗室自動化其實是「沒有 if 的程式」。
機器照稿跑完。
你隔天才知道爆了。
然後你再開一個新的 batch。
像在玩回合制 RPG。
你以為你在做科學。
你其實在做等待。
實驗室的 ENIAC 時刻:一堆線、一堆 GUI、一堆不互通的規格
現代實驗室常見的痛點是儀器被各自的 PC 與廠商軟體綁死,protocol 難以移植,資料格式常靠人手轉換。要跨儀器做條件分支(例如 OD 低於某值就餵養,否則取樣)往往變成多套系統重寫與人工同步,導致自動化停留在「固定腳本」而非「可自我調整的迴圈」。
你看到的不是高科技:你看到的是 1997 的幽靈。
有些儀器還真的要 Windows XP。
微軟自己都不想管了那種。😶
每台儀器一個 GUI。五個 driver。三個 license dongle。
你要改一個 protocol。
你不是在改「實驗」。你在改「整個堆疊」。
然後大家還會說「自動化很難啦」。
翻白眼。
人類其實很會:ASCII、UTF-8、G-code、STL 這種無聊共識才是王炸
歷史反覆證明,當整個產業同意一套機器可讀的輸入或輸出標準(例如 ASCII/UTF-8、CNC 的 G-code、3D 列印的 STL),互通性會讓成本下降、工具生態爆炸成長。生物領域的輸出格式(如 FASTA/FASTQ、PDB/mmCIF、流式細胞儀的 .fcs)相對成熟,但實驗「輸入側」仍缺乏類似 G-code 的通用協定。
標準這東西:很無聊。很人類。也很殘忍。
它會把「靠鎖客戶」的那套,直接打爛。
廠商最愛講一句。
「互通會讓我們變成烤麵包機。」
不會啦。
互通只會讓你變成「廚房」裡的某個強力設備。
然後廚房會變餐廳。
餐廳會變一條街。
錢會流進來。
你還可以靠準確度、吞吐量、維修、校正、UX 去賺。
不靠檔案格式勒索。拜託。
在台灣的畫面也很真:你去南港、生技園區、竹科附近繞一圈。
儀器採購常常是「標案思維」。規格表對得上就過。
互通性?
通常是「以後再說」。
然後以後就永遠不來。
這種文化超硬。
「時間 vs 金錢」算帳矩陣:你想省哪一種成本,自己選
Artificial Discovery 的核心不是浪漫,是算帳。你要把時間成本、現金成本、失敗風險攤開來看,才知道自己在玩哪一局。省時間通常要砸錢。省錢通常要吞時間。還有一種更陰的,省了兩個,風險爆炸。
- 低預算/低自動化:錢省下來了,時間被吃掉,實驗回合制跑到你懷疑人生;新人最常掉進去。
- 高預算/堆硬體但沒標準:錢砸很多,時間沒有真的省,因為整合、維護、重寫腳本像無底洞;看起來最先進,實際最卡。
- 中高預算/先做標準與OS層:前期花時間做協定、driver、資料管線,後面每個新實驗都像複製貼上;最像「投資」。
- 高預算/閉環自動化(感測+分支+重跑機制):時間省最多,錢也燒最多,適合有明確目標的團隊;燒不起就別硬裝。
我自己的偏見:堆機器不如先堆「能搬走的軟體層」。
機器會舊。
driver 跟 protocol 語言如果活下來,你才有複利。

你以為缺的是 AI,實際缺的是「濕實驗的 scaling law」
多數濕實驗領域缺少像摩爾定律那樣可預測的吞吐量與成果關係,因此資本不容易相信「加倍投入就會加倍發現」。盲目把實驗數量放大會遇到噪音、變異、物流複雜度與重跑成本,真正可行的路線通常是用 DOE、Bayesian optimization、active learning 等方法讓每一次實驗資訊量最大化,再配合平行化與小型化提升效率。
現實一點:濕實驗不是 cloud。
跑壞一次就燒掉一次試劑。
也沒有「免費重跑」。
你以為模型怪怪的可以再推一次。
實驗怪怪的你要再買一次。再排一次。再等一次。
還可能再怪一次。
超煩。
講到這裡,我反而想幫 DOE 平反:設計實驗(Design of Experiments)不是老派品管工具。
它是「用最少次數換最大資訊」的套路。
以前在製造業、農業試驗很常見。
現在 AI + 自動化一搭上去。
它很可能回來當主角。
那種感覺很像數論等了幾千年才被拿去做密碼學。
很扯。
工具落地(不要再只講願景):想讓 protocol 真的可跑、可追、可回溯,最基本要有版本控制與工作流管理。
- 版本控制:Git(把 protocol 當 code,才會有「誰改了什麼」)
- 工作流與排程:Airflow / Prefect 這類(把實驗當任務圖,不要靠人腦排)
- 資料與追溯:ELN/LIMS 概念要接起來(不然你只是在自動化產生垃圾)
- DOE:JMP、Minitab 這種傳統工具,或用 Python 生 DOE 設計(看團隊習慣)
講到 Git 我就想吐槽。
很多團隊連「protocol 有版本」都做不到。
你要閉環?你先別開玩笑。
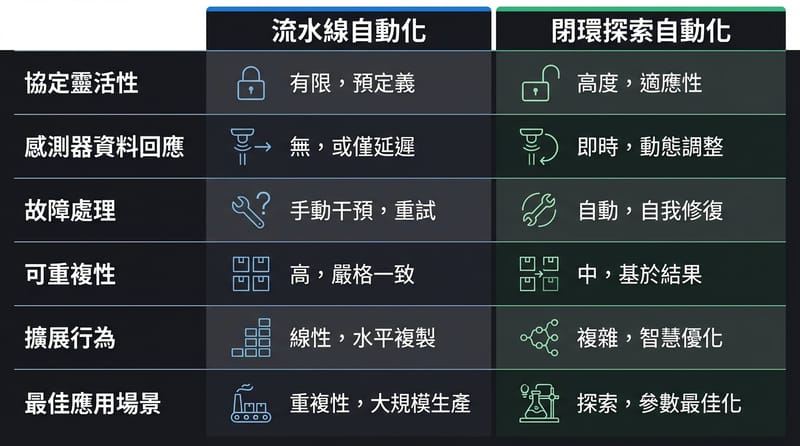
別把實驗室硬學 CPU,那會做出漂亮又脆的流水線
把實驗室比喻成 CPU 容易誤導,因為 CPU 的強項是固定硬體執行可預期指令序列,而 discovery 需要在執行中依感測結果改寫計畫、重配置流程圖。Artificial Discovery 的關鍵不是把實驗做成更快的 assembly line,而是把「重配線、分支、重跑與安全邊界」做成便宜、快速、可自動化的預設能力。
CPU 贏在不重接線:指令換一換就好。
實驗要贏:重接線要變便宜。安全。快。自動。
CPU 贏在拒絕重配線。Artificial Discovery 會贏在把重配線做成日常。
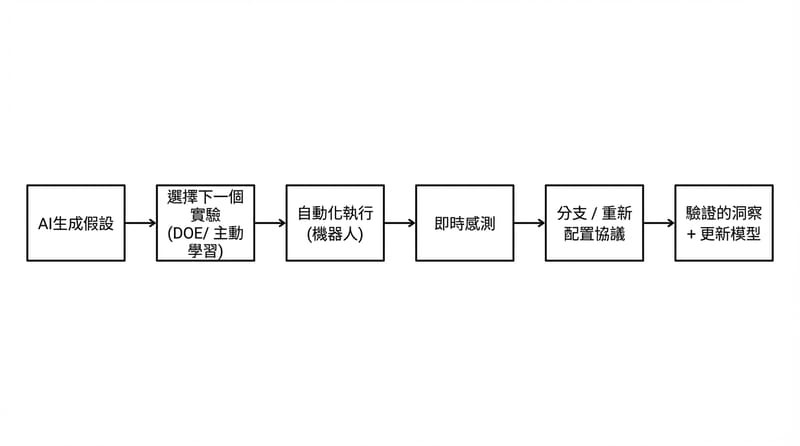
兩道牆:先補「回饋迴路」,再找「通用實驗原子」
推進 Artificial Discovery 常見的兩個突破方向是:把即時回饋與條件分支加進現有儀器與流程,讓系統能在實驗中修正;同時探索更高平行度、資訊量更高的新平台(如微流體、微滴反應、lab-on-a-chip、多模態 assay),尋找可重複組合的通用實驗原子(例如 perturb→measure→decide→repeat),並用公開指標追蹤「每單位實驗的有效發現產出」。
牆一:把 feedback 做進去。感測。分支。錯誤處理。自動重跑。
牆二:找到那個可重複組合的原子步驟。像 NAND 那樣。只是這次是濕的。
而且要能算。
「多做 10 倍,發現也跟著長」那種曲線。
投資人才會進來。
不然永遠是 demo。
題外話:台灣這邊其實有機會卡位在「OS 層」跟「標準/驗證」那塊。
我們很會做整合。
也很會做供應鏈。
缺的是「大家願意一起同意一套規格」。
這句聽起來像廢話。
現實就是最難的那種廢話。
我比較在意的真相:人類不是我們的智力,我們是我們少數的發現
在人類歷史上,智慧與內容產出極多,但真正改變世界的突破性發現相對稀少。當 AI 讓「產生想法與文本」變得廉價,稀缺性會集中到能否建立可重複、可迭代、可驗證的 discovery 系統,包括標準化的實驗語言、可移植的驅動層、與能自我修正的閉環實驗流程。
你看。
人類幾十億個腦袋。
幾千年。
最後你回頭數。
真正讓世界轉向的 discovery 其實不多。
這點很不舒服。
也很真。
AI 把智力變成便宜貨。剩下的貴,是把世界逼出一句「對,真的就是這樣」。
然後你會問:這聽起來很宏大,跟我有什麼關係?
如果你在做生醫、材料、化工、農業、甚至做製造流程最佳化。
你每天都在碰同一個瓶頸。
「想」很快。
「試」很慢。
你能不能把「試」變快。
或至少變聰明。
你就贏很多。
預判一下反對意見:一定有人會說「標準會扼殺創新」「每個實驗都不一樣哪有通用語言」。
我懂。
也不是完全錯。
你要是把標準做成教條,當然會窒息。
但你不做標準,大家就會一直在重寫同一種搬水腳本。
那種創新更可憐。
你覺得呢。
你站哪邊?


