
你是不是也常常卡在一種很尷尬的縫裡:寫程式寫到一半,突然被朋友丟一個「生物科技現在超缺工程師」的職缺連結,然後你心裡第一個念頭不是興奮,是「蛤?我要去穿實驗袍、拿移液器、背胺基酸縮寫?」
我懂。那個抗拒很真。
但現實是:生物實驗室正在變成一套可以被版本控制、可以被排程、可以被監控的系統,而軟體工程師那套「流程感」在這裡居然超好用。
寫程式的人轉進生技,不是跨界,是換一個資料更髒的戰場
生物科技之所以突然大量找軟體工程師,是因為定序儀、顯微鏡與自動化平台把實驗變成高密度資料問題:從 FASTQ、BAM/CRAM、影像到 assay readout,全都需要資料管線、工作流、版本控管與稽核,才能讓研究可重現、可追溯、可擴充。
- 你會看到:實驗數位化(ELN)、結構化 metadata、可查詢的時間線
- 你會碰到:便宜又普及的 pipetting robot、plate reader,開始吃 Python/REST
- 你會被逼著:把「模型漂亮」換成「資料乾淨 + 研究設計不坑」
- 你會習慣:雲端、容器、排程器,跑起來像 DevOps 但更怕污染
老實說:「硬體升級」不是 GPU,是一間像 CI/CD 一樣運作的濕實驗室。聽起來很科幻,實際上只是把混亂變成可控。
可控就值錢。
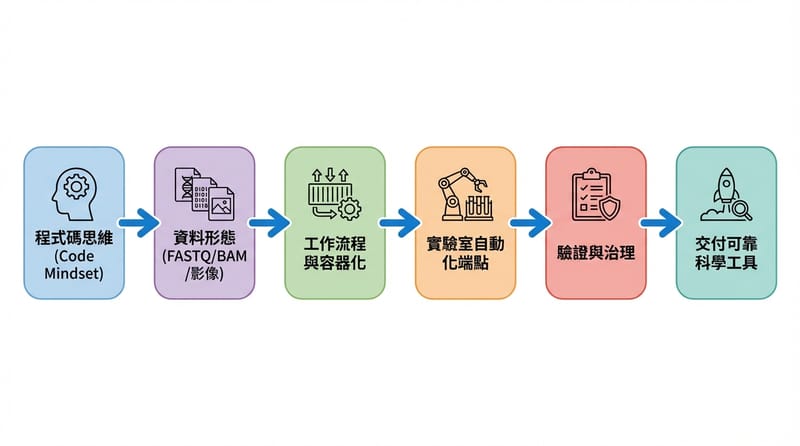
生技的「現代技術棧」翻成工程師語言,其實就那幾個部位
現代生技團隊的 bio stack 可以拆成「來源可信、資料落地、工作流計算、硬體自動化、分析建模」五層,對應到工程上就是 Git + Data Lake + DAG + 服務整合 + ML。
Source of truth:電子實驗紀錄(Electronic Lab Notebook, ELN)很像 Git log,差別是每個 assay 需要更完整的 metadata(樣本、protocol 版本、儀器、操作者、時間、條件),好一點的系統還會管 checksum、樣本 lineage。
你知道嗎,很多災難都不是「做錯」,是「做對但沒記清楚」。
Data layer:你會遇到 FASTQ(原始 reads)、BAM/CRAM(比對後檔)、count tables、影像 tiles。工程上就是 object store + columnar storage 的老朋友:Parquet、Arrow、chunked arrays 這些概念跑不掉。
分區、schema、lineage。那套你熟的。
Compute & workflows:生物 pipeline 很像 ETL 但步驟更「科學儀式感」。DAG 工具(像 Nextflow、Snakemake 這種)配上容器、immutable artifacts,重跑、續跑、cache,全部要能講清楚。
跑一個樣本沒什麼。
跑 2,000 個樣本你就會開始相信「可恢復性」是信仰。
Automation & hardware:機器人、儀器開始給 SDK 或 HTTP endpoint,你把它當 microservice 會很舒服:有 latency、有 retry、有 idempotency,然後也有那種「今天就是不想理你」的故障模式。
而且 concurrency limit 一樣會咬人,只是你排的不是 pod,是 plate。
Analytics & modeling:資料落地後,Python/R、notebook、向量化操作、模型(預測 binding、growth、yield)。Feature store 概念也能搬,只是特徵不是 clickstream,是序列和訊號。
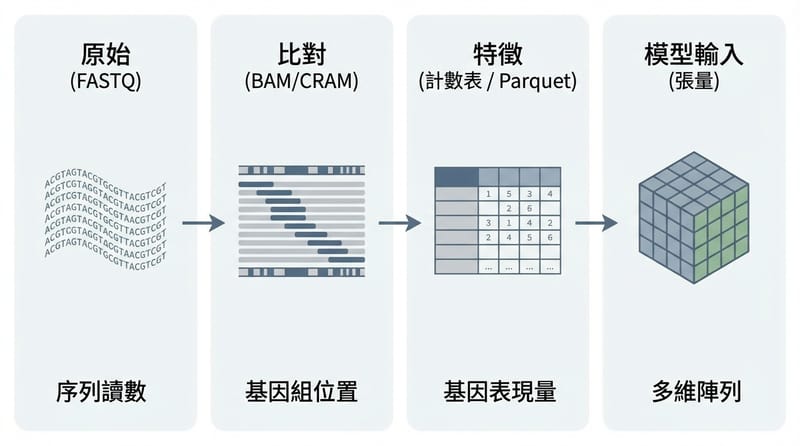
先別急著碰「改造生命」:從序列資料清潔開始就很夠用了
軟體工程師在生技最安全、也最常見的起手式,就是做「資料衛生」:讀序列、驗證格式、正規化、算一些基本統計(像 GC%)、做 motif 計數,然後把結果寫成乾淨的表格給分析用。
注意:下面這段只是在做序列的描述性計算,不涉及任何實驗操作、也不是基因設計;如果你在做真實生物樣本或人體資料,還要看公司 SOP、IRB/倫理審查與資料保護規範,這邊不要亂套。
# tiny_bio.py - sequence hygiene 101 (safe)
from pathlib import Path
def read_fasta(path):
seqs, buf = [], []
for line in Path(path).read_text().splitlines():
if line.startswith('>'):
if buf:
seqs.append(''.join(buf).upper())
buf = []
else:
buf.append(''.join(ch for ch in line if ch in 'ACGTacgt'))
if buf:
seqs.append(''.join(buf).upper())
return seqs
def gc_content(seq: str) -> float:
if not seq: return 0.0
gc = sum(1 for b in seq if b in 'GC')
return round(100.0 * gc / len(seq), 2)
def motif_count(seq: str, motif: str) -> int:
motif = motif.upper()
return sum(1 for i in range(len(seq) - len(motif) + 1)
if seq[i:i+len(motif)] == motif)
if __name__ == "__main__":
seqs = read_fasta("example.fasta")
for i, s in enumerate(seqs[:5], 1):
print(f"seq{i}: len={len(s)}, GC%={gc_content(s)}, ATG_count={motif_count(s, 'ATG')}")我以前在做資料管線的時候就有這種感覺:你 CSV 清不好,後面 dashboard 再漂亮都會騙人;序列也是一樣,先把輸入驗乾淨、統計算可靠,才談得上模型。
不然你只是把垃圾算得很快。
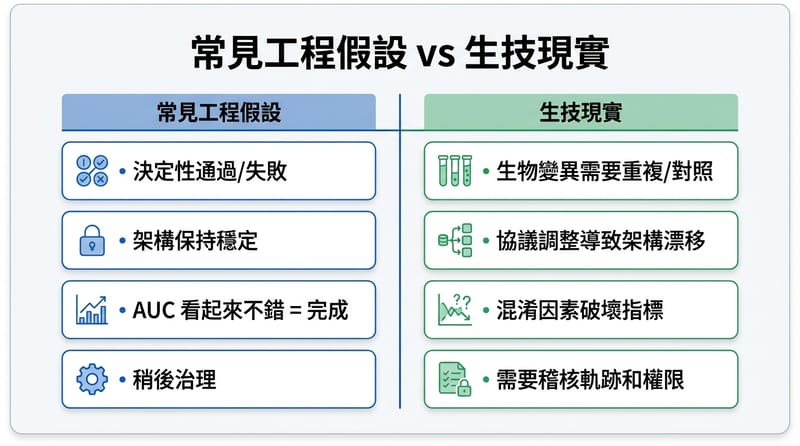
工程師帶進實驗室的,不是酷炫模型,是「可重現 + 可觀測 + 可排程」
在生技,工程師的價值常常不是寫出最聰明的演算法,而是把整個系統變成「能被相信」:同一份資料、同一個流程、同一組版本,跑出來要一致;出了問題要能追;資源要能排得進去。
可重現(Reproducibility):生物實驗很貴,pipeline flake 一次就是幾週不見。容器化、pin tool versions、參數記錄、immutable artifacts,這些做起來就是把「重跑成本」壓到你不會想哭。
在生技圈,「能重跑」不是潔癖,是生存。
可觀測(Observability):assay drift 很像 memory leak,慢慢壞、很陰、等你發現已經污染一整個 campaign。儀器 hiccup、plate-edge effect、batch issue,靠猜會死。
指標、追蹤、dashboard,這些不是加分題,是止血。
吞吐與排程(Scheduling):機器人 lane 會飽和、tip 會用完、incubator window 會錯過。排 plate 其實就是 bin-packing 加上一堆生物限制條件,工程師很懂這種痛。
懂就好。真的。
資料契約(Data contracts):跟科學家先講清楚欄位、單位、QC threshold、什麼叫 done,後面少掉一堆「欸你這欄怎麼變成字串」的災難。
這跟你寫 API contract 一樣,只是對方是拿著移液器的人。
哪些角色最適合?我看過的幾種「工程師在生技的活法」
生技找工程師不只一種缺,常見路線大概是這幾條:Bioinformatics、ML/AI(Bio)、Lab Automation、Data Platform、Scientist-facing Product。每條路的「爽點」跟「雷」不太一樣。
Bioinformatics Engineer:把 raw reads / 影像變成可用的 feature。你會很常寫 pipeline、處理格式、追 lineage。你也會很常被格式噁心到。
ML/AI Engineer(Bio):做結構、活性、產率預測,validation 會被放大檢視,因為錯了就不是點錯廣告,是研究方向整個歪掉。
Lab Automation Engineer:控制儀器、排程、做安全互鎖、稽核。你會開始懂「idempotent 不是口號,是避免把樣本毀掉」。
Data Platform Engineer(Biotech):資料存放、權限、稽核、資料集人體工學。這條看起來像傳統 data platform,但合規壓力比較黏。
Product Engineer for Scientists:做 UX、QC 視覺化、標註工作流、查詢工具。你會學到一件事:科學家不是不會用軟體,是他們沒空跟你玩「隱藏功能」。
題外話:講到「稽核」我就想到台灣很多公司一開始都覺得麻煩,等到要碰人體資料、或要跟醫院/學研單位合作,才發現流程沒留痕跡會很難交代。然後就開始補洞。
補洞很累。
分眾決策(If This Then That):你是哪一種工程師,就走那條比較不會受傷的路
這段我用「群組聊天」的方式講,因為你我都老手了,大家都怕走冤枉路。
- 如果你是 infra/DevOps 腦:你多半會在 workflow engine、容器化、排程、observability 這區最吃香。你會愛上「把 pipeline 變穩」這件事,雖然很不浪漫,但很值錢。
- 如果你是 data engineer:你就盯 data layer、schema、partition、lineage、access control。生技資料超大、超碎、還常常長得不像資料。你會覺得煩,但也會覺得「終於有人需要我」。
- 如果你是 ML engineer:先把 study design、batch effects、leakage traps 這些當成必修,不然你會做出一個 AUC 很漂亮、但科學上根本站不住的模型,然後整組人陪你重來。
- 如果你喜歡跟硬體打交道:Lab automation 那條路會很對味:SDK、HTTP endpoint、timeout、retry、safety checks。只是你要能接受,這裡的「失敗」不是 request 失敗,是樣本報廢。
- 如果你偏產品/前端:做 scientist-facing 工具其實很有意思:annotation、visual QC、query。你要抓的是「降低摩擦」,不是做花俏動畫。科學家會謝你,真的會。
對了,台灣這邊如果你在台北新竹跑一圈,很多討論會在一些社群(你知道那幾個)跟學研合作案裡冒出來,職缺也常常不是掛「Bioinformatics」那麼直白,有時候會包成「資料平台」或「自動化工程」。
就,很台灣。
常見翻車點:不是你不夠強,是生物世界不給你 deterministic
工程師剛進生技最常踩的坑,通常不是技術做不到,是心態還在用「單元測試 pass/fail」那套看世界。
坑 1:把實驗當成程式,忘了變異性。生物會飄,replicates、controls、effect sizes 這些要放在腦中最前面,不然你會以為自己抓到 bug,結果只是自然波動。
坑 2:silent schema drift。protocol 微調一下,下游就爆。要有 schema tests、changelog,而且最好人類看得懂。
坑 3:只盯模型指標。confounded dataset 會做出漂亮 AUC,然後把你帶去錯的方向。跟 domain expert 對 study design,這裡是硬仗。
坑 4:忽略治理(governance)。誰跑的、跑了什麼、用哪批樣本、為什麼跑,權限、audit log、可追溯性,這些在生技不是「之後再補」。
生物資料的「乾淨」不是美觀,是你能不能在兩個月後把事情說清楚。
30–60 天上手節奏:先把「小而可信」做出來,再談野心
如果你真的要切進來(或你已經在裡面但覺得亂),比較實際的節奏是:先熟 vocab 和資料形狀,再做一個 tiny pipeline,最後加上觀測與故障復原。
- 第 1–2 週:把 central dogma、DNA/RNA/protein、assay vs screen、replicates/controls 這些詞先放進腦袋。再挑一個公開、良性資料做分析(GC%、k-mer、影像 QC 之類)。
- 第 3–4 週:做一條小管線:read → validate → 算 2–3 個 feature → 寫出 tidy tables + 基本 plot。包起來、寫清楚怎麼跑。
- 第 5–8 週:加 logs/metrics、容器化、練 failure recovery。再做一次「交付給科學家」的假想:他要看到什麼才會信你?
節奏會長得很像軟體:design → run → measure → refine。
只是你跑的是細胞。

我自己的結論(比較像嘮叨):生技是一個「披著培養皿外衣的系統工程」。你把 invariants、contracts、feedback loops 帶進去,科學家的節奏會被你拉快,而且不是靠取代誰,是靠讓資料跟工具變得比較不會背叛人。
背叛真的很常見。
最後丟一個資源名詞:去查「Nextflow」的文件跟社群案例,很多你看得懂的工程語言,會突然把生物 pipeline 這件事講得很清楚。
就當作今晚睡前滑一下。😮💨


